Архитектура
DataSmelt.
Мы не просто храним данные. Мы используем алгоритмы для «плавки» сырых потоков из сотен источников в единый, чистый и мгновенно запрашиваемый сплав истины.
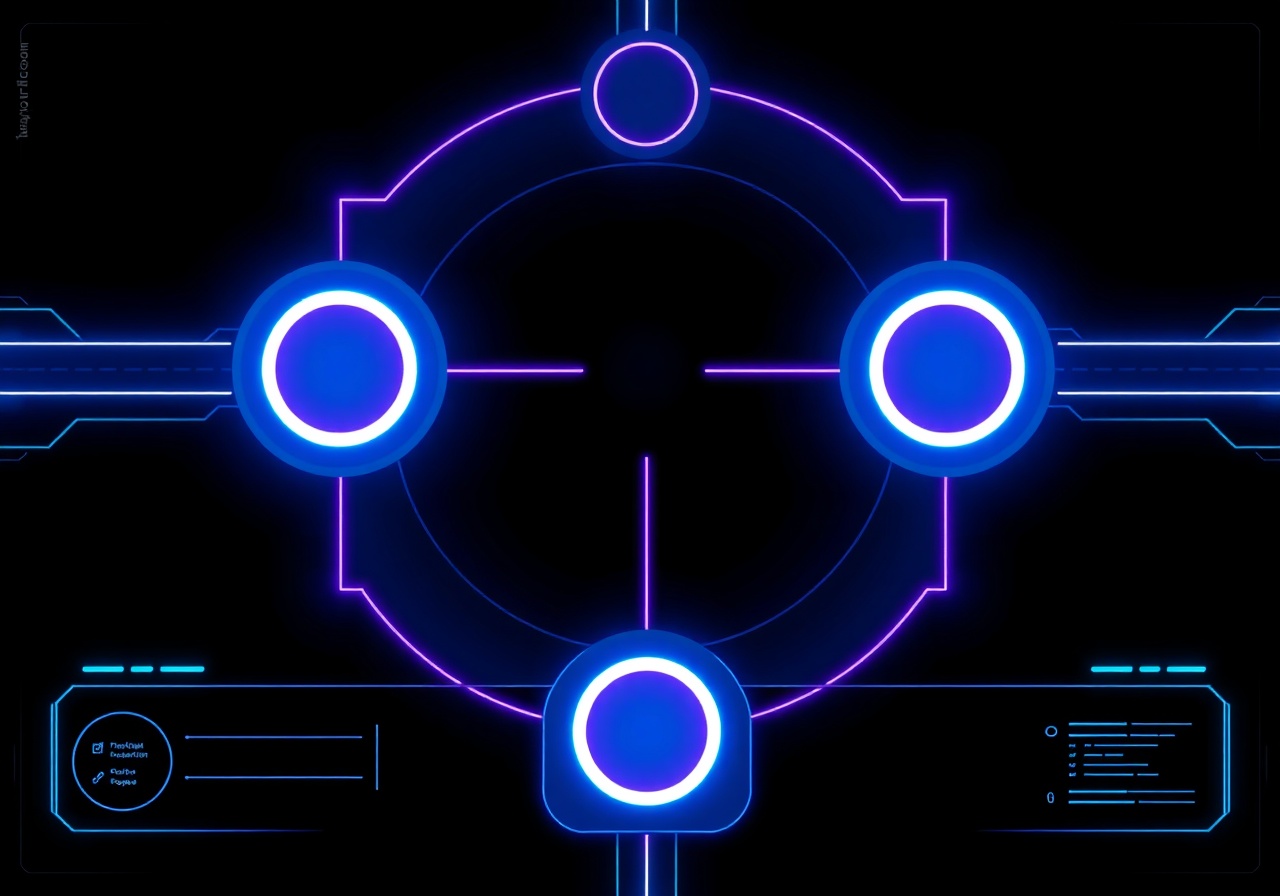
Процесс Плавки: От Хаоса к Кристаллу
Традиционные ETL-процессы устаревают. DataSmelt использует непрерывный цикл обработки данных, метафорически называемый нами «Плавкой».
1. Ингестия (Ingestion)
Сбор сырой руды. Мы подключаемся к любым источникам — от логов IoT-датчиков до транзакционных баз SQL. Данные поступают в систему без предварительной обработки, сохраняя максимальную энтропию.
2. Очистка (Purification)
Удаление примесей. Нейросетевой движок анализирует структуру, выявляет дубликаты, исправляет аномалии и сопоставляет семантику полей из разных систем (например, "client_id" и "cust_no").
3. Литье (Casting)
Формирование истины. Очищенные данные выливаются в единую «Truth Layer» — виртуальную базу данных, готовую к мгновенному запросу через SQL или GraphQL.
Единый движок запросов
Вам не нужно знать, где физически лежит таблица — в Snowflake, MongoDB или Excel-файле на сервере. DataSmelt предоставляет унифицированный интерфейс.
Наш Query Engine транслирует ваши запросы в оптимальные инструкции для каждой конкретной базы данных, агрегируя результаты на лету. Это позволяет аналитикам писать один SQL-запрос к всей инфраструктуре предприятия.
Поддержка ACID-транзакций на уровне виртуального слоя гарантирует консистентность данных, даже если источники обновляются асинхронно.
FROM smelt.sales_data
JOIN smelt.customer_profiles
WHERE date > '2023-01-01';
Скорость против Традиционных Методов
DataSmelt объединяет возможности потоковой обработки в реальном времени и надежности пакетной обработки, создавая гибридный слой, который работает со всеми типами баз данных одновременно.
Интеграция с вашим стеком
Мы не требуем миграции. DataSmelt накладывается на вашу текущую инфраструктуру как прозрачный слой.
Источники (Inputs)
SMELT
ENGINE